
Everything is Training Data Now
New AI models perform spectacularly well on many tests. But are they cheating?

In the good old days of machine learning1, we had a simple way to understand how good our models were. You would take all of your data and split it up, maybe 80% to 20%, or 90% to 10%, into a training set, on which you would train your model, and a test set, on which you’d test your model.
If you felt like being extra rigorous, you could set up an external set as well, a held-out dataset that you would evaluate on only after you “finalized” your model (in practice, researchers weren’t always so disciplined).
There are many different ways to do this splitting process. On my home turf in the life sciences, we would often split up datasets of molecules based on their chemical structure, aiming to measure our models’ ability to predict on “new” chemistry, or do time-based splits, training on data generated before a certain date and testing on data generated after that date.
The idea was that these approaches measured generalization – either into new chemical space or into the future. The goal is that at the end of the day you can say “my evaluation set looks like the examples my model is going to encounter in the wild, so since the model has 95% accuracy there, it should have ~95% accuracy for my users.”
There are still many ML papers that evaluate their models this way, and it’s considered a gold standard for certain tasks, like image recognition.
But the development of the most powerful LLMs has shattered this paradigm of training / test splits.
LLMs train on the entire internet, swallowing datasets whole — training, test, validation and all.
Data leakage, a.k.a. data contamination, is when a model trains on data that is in the testing or external set, inflating its performance with memorized answers.
The race for artificial general intelligence (AGI, or roughly an AI that can do everything humans can do) has led AI labs to sideline considerations of data leakage in favor of just get all the data now. The company with the best model can go out and raise previously unthinkable sums of money. For these historically capital intensive businesses (OpenAI spent $9B in 2024) that survive on fundraising, having the best model is a short-term question of life or death. A few pedantic nerds calling you out for training on the test data is not. Raise billions first, deal with data leakage questions later.
The problem is that this is muddying our conceptions of how good these models really are. Are they solving hard problems with intelligent reasoning, or just memorizing archetypes of problems and their solutions2?
Benchmarks
Benchmarks are the questions we ask LLMs to understand their capabilites. Let’s talk about the ARC-AGI benchmark, developed by Francois Chollet3. Here’s an example question, where the goal is to fill in the final grid with colored squares based on the pattern in the first two pairs of grids:
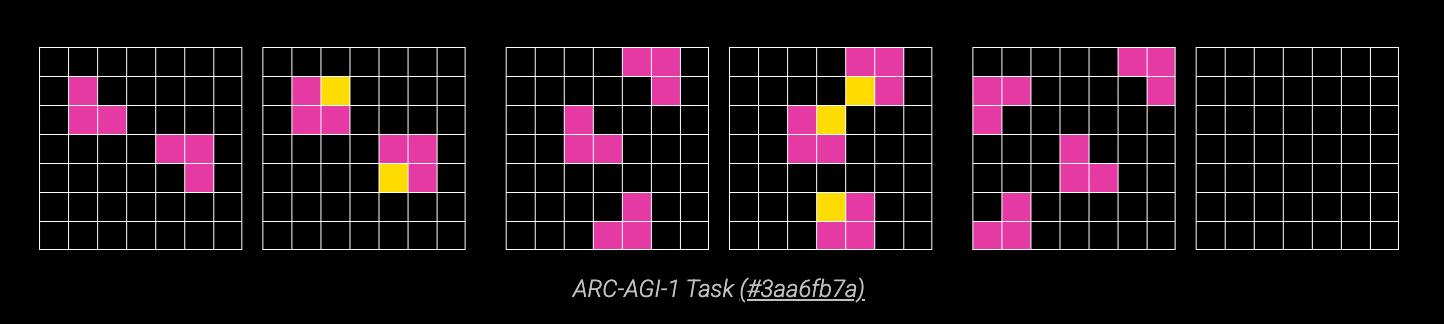
Try answering it yourself — pretty easy, right? It turns out LLMs have struggled with these types of tasks, because they require inferring the rules of a new game on the fly.
GPT-2 (2019) and GPT-3 (2020) achieved a whopping 0% accuracy on this benchmark. GPT-4o (2024) and GPT-4.5 (early 2025) were still less than 10% accurate. Humans, on the other hand, do very well: ARC-AGI estimates an average STEM grad would score ~98%4.
Then, earlier this year, OpenAI released a new class of reasoning models, the o-series (o1, o3, etc.). These models are trained on custom data painstakingly created by humans, and produce long “chains-of-thought” before answering questions. They appear to think through problems the way you might think through an interview question; they review and revise their previous reasoning as they arrive at an answer. OpenAI’s o3-high model achieved an eye-popping 88% accuracy on the ARC-AGI benchmark, leading even seasoned commentators to declare that AGI has been achieved.
But! It turns out that o3 was trained on a public dataset that ARC-AGI released as part of their challenge. So, what’s the big deal? The public dataset is public and the results that blew everyone’s minds were on a semi-private5 evaluation set. This isn’t data leakage. But the whole point of ARC-AGI is to assess a model’s ability to train a completely new skill. By training on ARC-AGI data, the goal of the benchmark — can the model learn the rules of a game it’s never seen before — may have been compromised (I don’t know how different the problems in the public set vs. the semi-private set were, though ARC-AGI says they used the same “structure and cognitive priors”). OpenAI did not release the results from reasoning models that weren’t trained on ARC-AGI problems — I assume that if performance was comparable, they would have.
Last year, the team at Epoch AI, a nonprofit research institute that studies AI, developed a benchmark for LLMs called FrontierMath, containing dozens of math problems that would be difficult for even professional mathematicians to solve. Here’s an example:
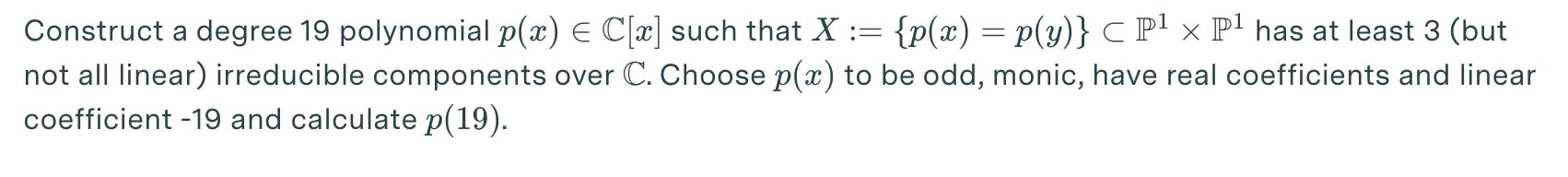
Good luck.
o3 seemed to be making remarkable progress on this benchmark, achieving an unprecedented accuracy of 25% (previous bests were around 2%). But after these results were published, it was revealed that OpenAI had been granted access to most of the problems in the dataset ahead of time. While they verbally agreed not to train on them, it surely gave them an advantage in selecting models, and affected their training strategy. Hands were wrung and apologies were made.
These are examples of what I would call benchmark gaming6: optimizing a model specifically for performance on a benchmark that is supposed to be a measure of general capabilities, or evaluating so often on a benchmark that overfitting occurs.
As any ML researcher knows, even having access to validation data, or example data for a task that was supposed to be completely novel, is enough to contaminate your model, and make its generalization to new data unclear. Goodhart’s law says that once a measure becomes a target, it ceases to be a good measure — and our measures are becoming targets at the clock speed of the massive GPU clusters running 24/7.
Humanity’s Last Exam (HLE), a benchmark developed at Scale AI which contains 2,500 questions across a wide variety of topics in physics, biology, humanities, math, etc7, comes with a public leaderboard of model performance. Of the 26 models listed on the HLE leaderboard, 21 (!!) carry this warning:
Potential contamination warning: This model was evaluated after the public release of HLE, allowing model builder access to the prompts and solutions.
Are the labs training on this dataset, or are they only using it for evaluation? We don’t know. In this highly competitive landscape, I think we have to assume these datasets are being trained on, unless the labs explicitly tell us they are not.
When OpenAI launched GPT-5 a couple weeks ago, there were some cherry-picked benchmark evaluations. For example, GPT-5 was evaluated not on the typical 500 coding problems in the software engineering benchmark SWE-bench Verified, but a subset of 4778, where it achieved 74.9% accuracy, a number that just edges out the performance of Anthropic’s latest model (Claude 4.1 Opus scored 74.5%)9. They also committed some egregious “chart crimes”:

I mean, come on. This bar-graph-felony was probably an innocent mistake, and the error bars on the numbers likely mean the difference between the OpenAI and Anthropic model are statistically irrelevant anyway. But how are we supposed to trust evaluation results when they’re presented in graphs with no error bars on mysteriously non-standard datasets?
I don’t mean to pick on OpenAI here — benchmarks are becoming harder to trust across AI companies. Whether it’s data leakage, benchmark gaming, or misrepresentation of results, it’s becoming harder to tell who’s ahead, and to trust that evaluation results will generalize to the real world.
This environment also disincentivizes researchers from doing the painstaking work of constructing new benchmarks. ImageNet, a database of images used for training vision models, has been cited more than 80,000 times. Every time someone reports results on ImageNet, we basically know what they trained on and how they evaluated their model. The more successful an LLM benchmark is, on the other hand, the more likely that it slips into the training data for the models, and quickly becomes irrelevant10. Our old ML training methods were a way not to escape Goodhart’s law, but to forestall it. Even ImageNet performance eventually just measured overfitting. Now, highly publicized benchmarks for LLMs end up being one-use-only.
More and more papers and benchmarks are including warnings like the one below, but 1) frontier labs may or may not be paying attention, and 2) all it takes is one twitter user to post a question from this dataset for it to leak into the training data for the models.

How good are the models, really?
I think the latest reasoning models are unbelievably impressive. I use them a lot in my work, and they can solve a ridiculous variety of problems. They’re a lot better at math competitions than I ever was. I’m not arguing that these models aren’t going to change the world. They will.
But to those of us interested in AI progress, or just interested in using the best model for our own ends, this setup has created a fog of war where it’s hard to tell when a benchmark result has been contaminated or gamed.
The lack of clarity regarding model performance on “novel” tasks makes it harder to determine if these models will actually help us in real world scenarios. It also makes it hard to assess how close we are to AGI. It was interesting that after the GPT-5 announcement, some commentators increased their AGI timelines. This seemed to be mostly based on vibes — if astounding leaps in performance were being made, why would you game your benchmarks (or generate some of the most misleading bar graphs of all time)? The frontier labs want you to switch to their newest model as soon as it is released, but the way the model feels to use often doesn’t match benchmark results — and I suspect data leakage and benchmark gaming is a big reason why.
GPT-5, o3, Claude Opus 4.1, etc. are astounding tools. But I remain just a little bit skeptical that they are really capable of solving 25% of novel problems as hard as FrontierMath, or achieving 90% accuracy on novel brain teasers a la ARC-AGI.
There are other ways to evaluate models, but they are still subject to manipulation. There are arenas like LMArena, where users judge LLMs against each other head-to-head on language, image, and coding tasks, math arenas, and design arenas. They don’t measure exactly what we want — users seem to prefer responses that are longer, with more citations, but not necessarily more accurate — but they are still a helpful measure.
And again, frontier labs keep gaming the benchmarks: earlier this year, Meta released its newest Llama 4 models, claiming better performance than OpenAI or Anthropic on LMArena. But it was quickly discovered that the model tested in the arena was specifically fine-tuned to please human evaluators. The real, more general model released to the public, performed much worse. The LMArena folks clarified that “Meta’s interpretation of our policy did not match what we expect from model providers.”
How do we deal with this?
One approach, which a lot of ML folks I know have applied liberally, is to curate private benchmarks (though, unless you explicitly tell them not to, the labs are training on those, too). This guy’s personal benchmark was whether the models could draw an SVG of a pelican on a bicycle (unfortunately due to its popularity this benchmark is probably now cooked? You can have it draw a sea turtle making an omelette or something). I still do a lot of benchmarking with simple arithmetic questions, coding tasks, or molecular description tasks:

If you’re interested in model progress, you should probably make your own private set of questions to assess model performance on the tasks you care about. The more standardized you can be, the better — evaluating based on vibes alone is not consistent. Even OpenAI effectively evaluated on their own “private set” in the GPT-4 paper — they looked at accuracy in their own codebase! And to their credit, they also performed some pretty detailed checks for dataset contamination.
Last year, the team at Scale AI demonstrated a fantastic way to detect dataset contamination in the wild. GSM8k is a dataset of more than 8,000 Grade School Math problems, like: “James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?”
The Scale team paid humans to generatea new set of 1,000 word problems, matched in difficulty and style to GSM8k. They then evaluated state of the art LLMs against this new dataset (which they creatively named GSM1k), and looked at the difference in performance:

The only reason a model would have statistically worse performance on GSM1k is if it was overfit to GSM8k! This elegantly shows the extent to which benchmark gaming or data contamination is causing us to overestimate model performance. You can see that some frontier labs are consistently worse than others — OpenAI and Anthropic seem to have diligently avoided data leakage or overfitting in this problem space. You can also see that the effect, at least in this domain, is certainly significant but not massive — the biggest gap is only about 13% worse performance. GSM1k-like datasets, which are matched to existing benchmarks but totally novel to the models, are a litmus test that can distinguish genuine model performance from overfitting.
Benchmarks like Humanity’s Last Exam, FrontierMath, ARC-AGI, etc. are the Google Maps directions that we follow to get to better models. If we want to improve the models in a way that doesn’t just look good on a slide, but helps people solve problems in the real world, we need to fix these distortions — data leakage, benchmark gaming, and performance misrepresentation — and continue the arduous but vital work of building new benchmarks.
There are many other wild consequences of LLMs having access to the whole internet, which I’ll cover in a future post. Thanks for reading.
A period I would personally define as 2012-2022, from the publication of AlexNet to the release of ChatGPT.
There’s a long philosophical discussion to be had about the difference, but I’ll save that for another day. Some argue that if the training corpus is large enough, for many tasks the useful difference between overfitting and generalization goes to zero.
Who I remember as the creator of Keras, because I’m a dinosaur.
They don’t estimate what they think a humanities grad would score, oof.
I’m still not 100% sure what semi-private means.
Basically, overfitting.
The data quality of this benchmark is up for debate — FutureHouse recently published a blog post suggesting that about 30% of HLE’s chemistry/biology answers are likely wrong.
OpenAI has also used this subset in the past, I believe because those 23 examples are difficult or impossible to run.
But again, note that this is on the 500 problems, not 477. Also, GPT-5 performance is listed at 74% on the GPT-5 system card here, which is confusing.
One plausible mechanism for this is just people posting questions from the benchmark online, without the canary string. Whether this is done maliciously or not, it will result in data contamination.
This was great, thanks! Can I ask 2 questions:
1. You write that OpenAI should be showing error bars on these evaluations. What would those error bars capture? Do you have in mind that they'd run the model many times on the same problems (with some nonzero temperature) to capture the uncertainty in the total % correct that comes from the fact that the output is probabilistic? Or do you have in mind something deeper and closer to the way we usually think about inference from random sample, i.e. there's some underlying "population" of problems and we're interested in the AI's accuracy in this more general population, but we're only observing a random sample of those problems in a benchmark?
2. Data leakage doesn't actually seem so easy to define -- whether or something is data leakage or not seems to depend on whether we're claiming the AI **should** be able to generalize. In some cases this question seems clearer than others. If the problem "x = 2y, solve for y" is in the training set and the AI can solve it, but not "x = 3y, solve for y", is that an example of data leakage? What about "x = 3y+1, solve for y" or "If x is three times as big as y, then y is ___ as big as x"?
You can imagine very easily generating stochastic versions of these benchmarks that perturb certain small details every time they're run to ensure that the AI has never seen the *exact* problem, but for practical purposes isn't this essentially still an instance of data leakage if our claim is the broader "AI should be able to solve a broad class of linear algebra problems" rather than the narrower "AI should be able to solve any problem of the form x = Cy"? And zooming back to the real world defining what the "broad class of problems" we want the benchmark to be representative of seems very difficult too. Maybe this is what benchmarks like SWE-bench are trying to solve --- but e.g. if the AI learns how to fix a specific bug from a GitHub issue in the training set and then is able to solve that bug in many different contexts, then (1) isn't this still useful even if it might be considered an example of data leakage and (2) how far do those contexts have to get from the original code so that it becomes "true knowledge" rather than data leakage"?
Awesome stuff!